The sheer volume of security alerts generated by a SIEM can be overwhelming, and it is critical that security teams are able to prioritize the alerts that could stop a potential attack in its tracks. This blog post reviews how SIEM alerts are generated and the basic steps a security team can take to set alerts that help them sort through the noise and find what matters – fast.
One of the core foundations of effective security monitoring, detection, and response (MDR) is having the right alert rule content. This allows your security operations center (SOC) and security teams to detect and respond to the vulnerabilities, threats, and attacks that are relevant to your environment. Without current, curated, and effective security content, it doesn’t matter how good your tools are, how many logs you collect, or how much environment visibility you have – the volume of raw noise is just too high for any SOC to wade through and find valuable security outcomes.
Setting Alert Rules
In the security monitoring space, an alert is created by a security information event management (SIEM) tool. When a set of conditions is met, the SIEM creates an indicator of an attack (IoA), an indicator of compromise (IoC), or other events worthy of investigation. These alerts are then gathered and analyzed by skilled SOC teams in the context of the organization’s environment and users to determine whether the alert is malicious, benign, or requires more investigation. This can lead to incident response or other remediation actions and outcomes.
A SIEM’s alert rules can be as simple as looking for a data field that contains a specific value, such as:
For example, an alert rule for an IP address that is known to be malicious might detect it among a firewall’s incoming accepted connections logs. Many newer tools allow alert rules to be based on a more complex chain of events – such as detecting events that map to the cyber kill-chain, decoding specific packet captures, and ultimately detecting Metasploit Meterpreter commands within them.
Simple rules can be expressed as search strings, while more complex rules may need to be defined as regular expressions (RegEx) or custom-scripted code detectors such as Python.
SOCs spend quite a bit of time curating their security content, which follows a specific life cycle (see Figure 1). This includes creating new content to detect the latest threats, and optimizing or retiring older content that may not be relevant anymore. Keeping older or obsolete rules active may cause system performance degradation, so maintenance is essential.
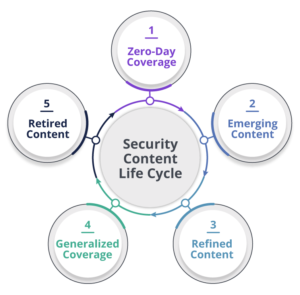
Figure 1: The security content life cycle
Alert rules apply to log messages, which are generated from the many different devices and applications that are deployed within an organization’s environment. These logs are commonly referred to as SIEM data, which is then monitored for signs of threats and suspicious activity.
But checking SIEM data for values can be difficult because there is no standardized format for the information that these messages contain. Parsers can be developed that read these messages and normalize the data into a standard model. Alert rules can then effectively check across all of the correlated, aggregated device data for threats.
The standardized data model also makes the occurrences of specific values on specific devices or applications more obvious. This is useful when two SIEM messages have the same error code but come from different sources, enabling analysts to unify different deployments’ content across a cloud and a local corporate network (see Figure 2).
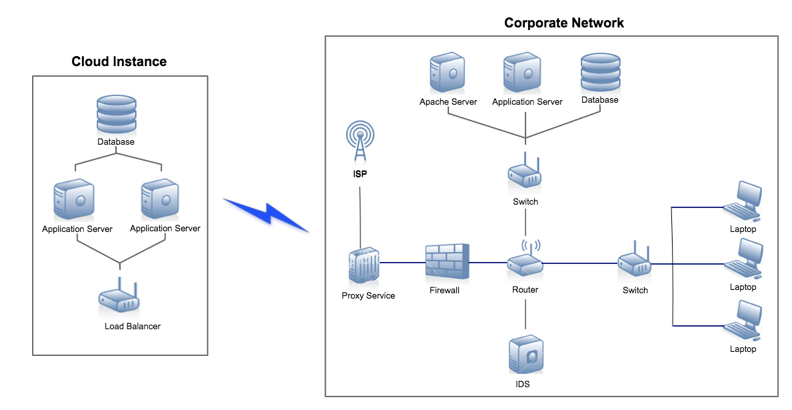
Figure 2: Each of these devices produces SIEM data that can be analyzed by security content and used to trigger alerts.
Alert Triggers
In general, when an alert is triggered, it is assigned a priority based on:
The node criticality is determined when the device or application is set up to send its SIEM data to a security platform, which can be on-premise or maintained by a security provider off-site. The alert rule priority is set using RegEx to check for values in the standardized data model. Threat intelligence provides known-malicious values, such as file hashes or IP addresses. All these values come together and assist the SOC team in determining which alert gets investigated first.
Better Alerts Mean Less Noise
A major challenge in researching and developing new alert rules is creating effective strategies to identify system attacks and anomalies. Since alerts are the basis of security monitoring, SOCs must constantly balance efforts to reduce false positives and prevent floods while still alerting on all suspicious activities. From a security research perspective, it is also imperative to continuously look for opportunities to improve alerts to reduce the false positive rate and increase true positive detections.
One way of increasing true positive detections is by writing alerts with better conditions that more specifically characterize actual threats, such as a Windows brute force attack. Event code 4625 in Windows means a failed login attempt. A rudimentary approach would be to alert whenever the SIEM receives a log with event code 4625 in Windows. But since users often mistype their passwords – typically a non-malicious event for most environments – it wouldn’t be necessary to generate an alert each time.
A solution is to alert only when multiple failures occur in short succession, which is where the idea of thresholding can help. Thresholding allows organizations to adjust the conditions based on their unique environments. Five failed logins within a few seconds may be reasonable for smaller organizations. But the threshold can be higher for a larger business where the volume of mistakes is expected to be greater.
It also helps to define the terms more clearly. For example, a brute force attack may be defined as “many failed logins followed by one successful login.” Although alerting on this behavior certainly is better than alerting for each failed login, more information can be gathered from other logs:
These indicators could be used to automatically create a criticality rating for the alert based on contextual evidence.
Another way to reduce alert noise is to look at different device workloads. For example, when monitoring traffic on a firewall device, certain packets will be denied and others will be allowed based on the criteria set by the firewall vendor.
From an alerting perspective, denied traffic is not that interesting. It simply indicates that the technology is doing what it is supposed to do. On the other hand, suspicious traffic that is allowed by the firewall could indicate a successful exploit attempt or other nefarious activity. Security analysts can use this additional information to distinguish between alerts that require investigation – and informational alerts that provide a trail for future investigations if needed.
Many businesses do not have the resources to monitor their entire network and so must prioritize which nodes to monitor. In determining alert criticality, analysts must understand the businesses’ unique network architecture. To get the best security value without monitoring everything, organizations can start by monitoring devices responsible for security controls, such as firewalls, IDS/IPS, and domain controllers.
The Art and Science of Writing SIEM Alerts
These are just some techniques that can help security teams overcome hurdles associated with crafting alerts for SIEM data. It’s not always as easy as creating a notification if some value occurs. Often, analysts must consider the organization’s environmental contexts and concerns, and what suspicious activity might look like.
Cybersecurity vendors that offer managed SIEM services will prioritize devices based on their criticality to a customer’s business, and leverage guided machine learning to establish and tune alert thresholds and detect anomalies automatically. They utilize next-generation techniques to understand what “normal” activity looks like on different systems. Combined, these efforts enhance their success in detecting and responding to IoAs or IOCs before they can cause damage.
SilverSky can remove the complexity of managing your SIEM and make it work for you. Learn more about our SilverSky Managed SIEM and active monitoring services.