Change the Rules of Engagement
The world’s leading Managed Detection & Response platform
What we do
Trusted by











Our Core Values
Vision
Velocity
Vigilance
The Vigilance to combine military-grade behavioral tracking and machine learning, together with human analysis and support, to protect our customers’ attack surface as vigorously as their bottom lines.
Our authority to operate in some of the most sensitive government networks puts compliance at the core of our company.
Change the Rules of Engagement
With over twenty years of experience in cybersecurity, we’ve learned the best way to stay ahead of the game, is to change it.
Schedule a demo to see how we can change your business for the better.
EXTENDED DETECTION
AND RESPONSE (XDR)
Managed Detection &
Response (MDR)
Managed Endpoint Detection & Response
EMAIL PROTECT
NETWORK PROTECT
INSIGHT
CYBER ADVISOR SERVICE
Aware
CONNECT
SECURITY CONSULTING SERVICES
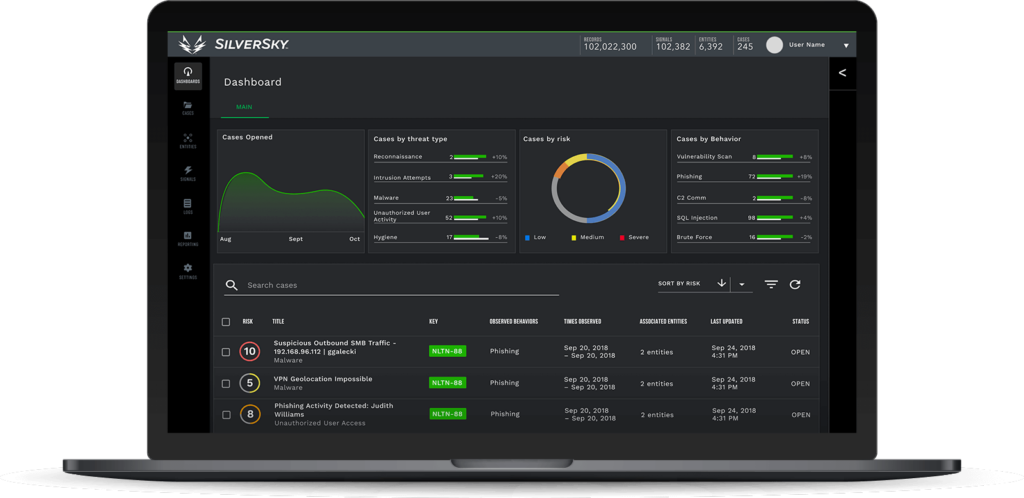
CONSOLIDATE YOUR SECURITY TECHNOLOGIES INTO A SINGLE VIEW
Our partners
Change, before you have to
Insight
Managed Detection and Response
Network protect
Managed Endpoint Detection and Response
cyber advisor service
Email Protect
Extended Detection and Response
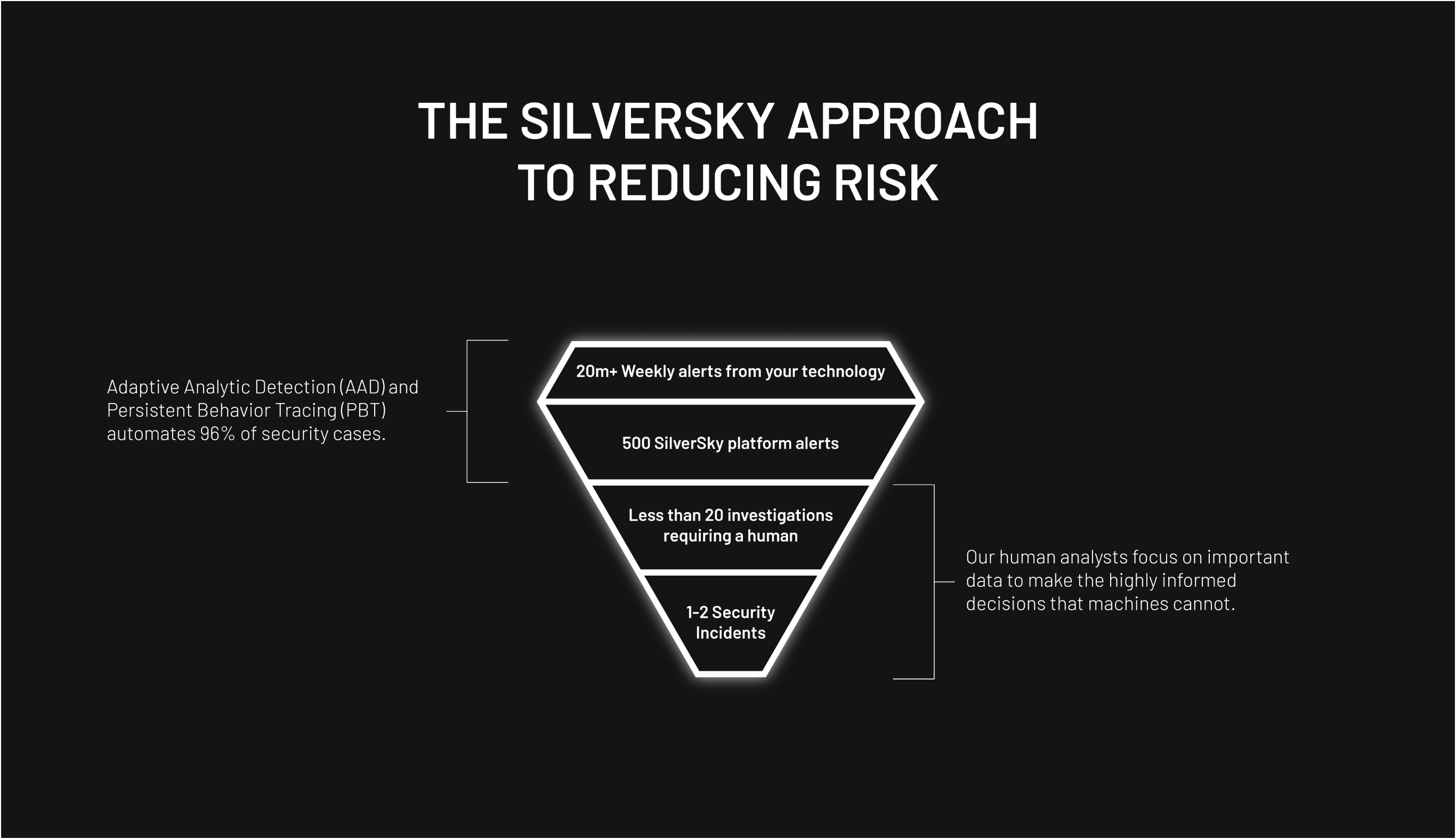
Technology Scales, People Don’t
Our authority to operate in some of the most sensitive government networks puts compliance at the core of our company.
With over twenty years of experience in cybersecurity, we’ve learned the best way to stay ahead of the game, is to change it.
Schedule a demo to see how we can change your business for the better.
Explore SilverSky’s MDR Platform
Book a demo and see how SilverSky changes the rules of engagement.